
As a router and a switch are advanced, it has started to support Software Defined Network (SDN)
technique which enables dynamic, programmable, and efficient network configurations.
Since proposed in 2009, it has become the most promising architecture for large-scale networks.
SDN protocols (e.g., OpenFlow from Google) in a router or a switch require rule tables to
classify packets floating around the networks. It basically checks a specific field in the
packet and compares with rules on the table. For the comparison, most of architecture uses
Ternary Content Addressable Memory (TCAM).
Problem Statements and Motivation
However, using TCAMs on SDN protocols has two main limitations:
(1) Different length of rules in the protocols – Because of the length difference of the rules, many architectures reserve long memory address spaces which should be at least same length as the longest rule. However, if the long rules are not many in the rule table, we waste all the empty remaining memory spaces in short rule address spaces.
(2) High power consumption due to the use of TCAM – General TCAM design consumes high power consumption.
Goal
To solve the aforementioned limitations, our group proposes a new TCAM circuit design. A core idea of our implementation is from previous paper (Chen et al.). Due to the limited padframe space, we scaled down to less number of bits and rows on our design.
Here are contributions (impacts) of our design:
- Enabling dynamic reconfiguration for number of bits to search by implementing mode scheme
- Combination of NAND TCAM and NOR TCAM lowering power consumption and still giving good filtering performance
- Improve throughput using a pipeline between NAND gates and NOR gates
In this project, we demonstrate how feasible and practical to use our design by explaining from high level to all the way down to low level (e.g., Pins used) and by showing simulation results and performance.
Design Overview
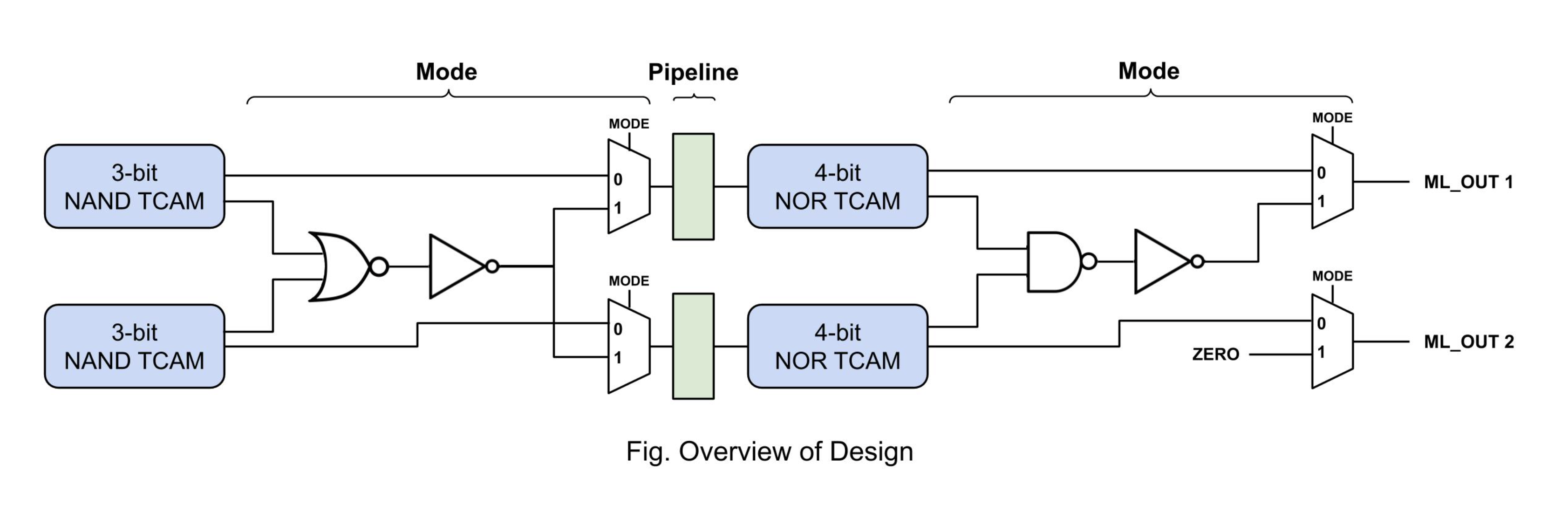
The figure shows an overview of our circuit design. As mentioned in introduction, we scaled down to less number of bits, 3-bit NAND TCAMs and 4-bit NOR TCAMs. Also, we implemented two rows (7bits in single row) in the design. However, scaling up from our design will not take much time, and it is just engineering work. Between NAND TCAMs and NOR TCAMs, we inserted mode multiplexer and pipeline. Pipeline divides search operation into 2 stages, separate NAND TCAM search and NOR TCAM search, and this almost doubles overall throughput. Mode multiplexer enables dynamic reconfiguration of number of bits by joining two rows. In mode 0, two rows operate individually, and those join together when the mode is 1.